딥러닝을 제대로 학습시키기 위해서는 많은 데이터를 필요로 한다. 또한, 그만큼 일반적인 경사하강법(GD ; Gradient Descent 또는 Batch GD)을 사용할 경우 한 번 업데이트할 때마다 모든 데이터를 미분해야 하므로 계산량이 매우 많아 시간이 무척 오래 걸린다. 또, 최적의 해를 찾기위해 충분히 반복하여야하며, local minima나 saddle point에 걸려 잘못된 해를 찾을 수도 있으므로 여러 곳에서부터 최적의 해를 찾아봐야하므로 더욱더 많은 시간을 걸린다.
이러한 점을 보완하기 위해 개선된 경사 하강법이 등장하였다.
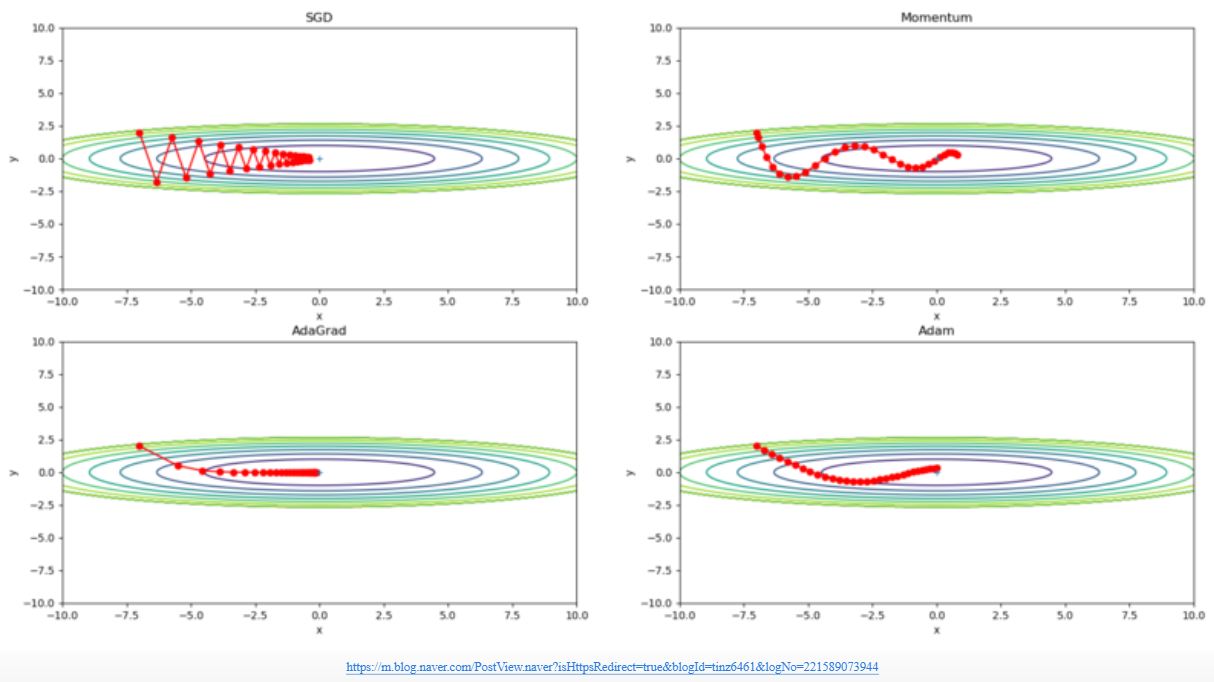
확률적 경사 하강법 ; Mini-batch Stochastic GD
모든 데이터를 사용하는 것이 아니라, 랜덤하게 추출한 일부 데이터를 사용하여 더 빨리 그리고 자주 업데이트하여 최적의 해를 찾는 방법이다.
랜덤한 일부 데이터를 사용하기 때문에 중간 결과의 진폭이 크고 불안정해 보일 수 있지만, 속도가 확연히 빠르면서 최적 해에 근사한 값을 찾아낸다.
Mini batch의 크기는 클수록 메모리를 많이 사용하지만(메모리에 많은 데이터를 올려놓고 학습하므로) 안정적으로 학습한다. 하지만 과적합될 가능성도 그만큼 커진다.
Mini batch의 크기가 작으면 메모리를 적게 사용하지만 학습이 불안정해지지만, saddlepoint나 local minima에 안착할 가능성이 적어진다.
그러므로 보통 batch_size는 32 또는 64를 사용하는게 일반적이다. (2의 제곱을 쓰는게 일반적으로 computer 계산에 최적화된다.)
엄밀히 말하자면 다르지만 보통 SGD, MGD, MSGD 모두 같은 뜻으로 쓰인다. 자세히 알고 싶다면 여기

모멘텀 SGD ; Momentum SGD
SGD에 탄력을 더해 오차를 수정하기 전 바로 앞 수정 값과 방향(+, -)를 참고하여 같은 방향으로 일정한 비율만 수정되게 하는 방법이다.
따라서, 수정 방향이 양수(+) 방향과 음수(-) 방향으로 지그재그하는 현상이 줄어들고 관성의 효과를 낼 수 있다.
Nesterov Momentum ; Nesterov accelerated gradient ; NAG
먼저 관성에 따라 이동하고 경사하강법을 적용하여 가중치를 업데이트한다.
Adagrad와 RMSProp
Adagrad는 Gradient 히스토리 h 에 Gradient(경사, 기울기) 값을 계속 누적시켜 가파른 부분에서 학습률
RMSProp은 여기에 Gradient 히스토리도 마치 위에서 봤던 momentum처럼 관성적이게 만든것이다.
공식
Adagrad
RMSProp
adam
Adagrad와 Momentum을 합친 것으로 거의 디폴트로 사용되고 있는 optimizer이다.
댓글