구간 분할 binning
데이터 분석 알고리즘에 따라서는 데이터를 그대로 사용하기 보다는 일정한 구간(bin)으로 나눠서 분석하는 것이 효율적인 경우가 있다. 나이, 가격, 비용, 효율, 지역, 품종 등 수준이나 정도를 일정한 구간으로 나누고, 각 구간을 범주형 이산 변수로 변환하는 과정을 구간 분할(binning)이라고 한다.
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', ordered=True)
데이터 값을 분할하고 구간별로 정렬해야 할 때 사용하십시오. 이 함수는 연속형 변수에서 범주형 변수로 변환하는 데도 유용하다. 예를 들어, 연령대를 연령대 그룹으로 변환할 수 있다.동일한 수의 빈 또는 미리 지정된 빈 배열로 구간분할하는 것을 지원한다.
매개변수 Parameters
x 배열종류( 시리즈Series, ...)
구간분할하려는 배열 데이터.
1차원 배열이여야 한다.
bins 정수형 int, 순차적인 원시값 sequence of scalars, 구간인덱스 IntervalIndex
구간 경계 기준값
- 정수형 int : 매개변수 x의 범위에서 같은 폭으로 나눌 구간의 수를 규정한다. 매개변수 x의 범위는 매개변수 x의 최소값과 최대값을 포함하도록 양쪽에서 .1%까지 확장된다.
- 순차적인 원시값 sequence of scalars : 구간의 경계를 규정한다. 매개변수 x의 범위를 확장하지 않는다.
- 구간인덱스 IntervalIndex : 사용할 정확한 구간을 규정한다. 구간인덱스 IntervalIndex의 구간은 겹치면 안된다.
right 불리언 bool, default True
구간의 가장 오른쪽 경계값을 포함할지를 결정한다.
False일 경우 왼쪽 경계값을 포함하게 된다.
이 매개변수는 bins 매개변수에 구간인덱스를 줄 경우 무시된다.
labels 배열array 또는 False, default None
반환될 구간의 이름을 지정한다.
배열의 길이는 구간의 수와 같아야한다.
이 매개변수가 None일 경우, 구간의 이름을 구간인덱스로 반환한다.
이 매개변수가 False일 경우, 구간의 이름을 구간인덱스의 인덱스 순서로 반환한다.
이 매개변수는 bins 매개변수에 구간인덱스를 줄 경우 무시된다.
이 매개변수가 True일 경우, 예외가 발생한다.
매개변수 ordered=False일 경우, labels은 None이나 False가 될 수 없다.
retbins 불리언 bool, default False
경계값 배열을 반환할지 결정한다. 경계값을 알고 싶을 때 유용하다.
precision 정수형 int, default 3
구간 경계값을 저장하고 표시할 정밀도
include_lowest 불리언 bool, default False
첫 경계값을 왼쪽 구간에 포함포함시킬지 여부
이 매개변수는 매개변수 right=False일 경우 무시된다.
duplicates {‘raise’, ‘drop’}, default 'raise
구간 경계값이 유일한 값들로 이루어지지 않을 경우 때
'raise'일 경우 ValueError가 발생한다.
'drop'일 경우 중복된 값을 삭제한다.
ordered 불리언bool, default True
구간명의 순서 지정 여부.
이 매개변수가 True일 경우, 반환되는 카테고리에 순서가 지정된다.
이 매개변수가 False일 경우, 반환되는 카테고리에 순서가 지정되지 않는다. (매개변수 labels를 반드시 지정해줘야 한다.).
판다스 1.1.0. 버전부터 사용할 수 있다.
반환되는 것
out 범주형Categorical, 시리즈Series, or ndarray
매개변수 x의 각 값에 해당하는 구간을 나타내는 배열유형의 객체.
자료형은 labels의 값에 따라 다르다.
- None (default) : 매겨변수 x의 값이 시리지일 경우 시리즈를 반환하고, 다른 모든 유형의 경우 범주형을 반환한다. 배열 내부에 Interval dtype으로 저장된다.
- 순차적인 원시값 sequence of scalars : 매겨변수 x의 값이 시리지일 경우 시리즈를 반환하고, 다른 모든 유형의 경우 범주형을 반환한다. 배열 내부에 순차적인 원시값의 자료형이 무엇이든지 상관없이 저장된다.
- False : 정수의 ndarray를 반환한다.
bins numpy.ndarray 또는 구간인덱스IntervalIndex.
계산되거나 지정된 구간값.
매개변수 retbins=True일 경우에만 반환한다. For scalar or sequence bins, this is an ndarray with the computed bins. If set duplicates=drop, bins will drop non-unique bin. For an IntervalIndex bins, this is equal to bins.
import pandas as pd
# 데이터 프레임 만들기
df = pd.DataFrame({'horsepower':[50,330,80,300,100,280,120,250,150,222,188,200]})
# 예제
df['hp_bin1'] = pd.cut(x = df['horsepower'],
bins = 3,
)
df['hp_bin2'] = pd.cut(x = df['horsepower'],
bins = 3,
precision = 1
)
df['hp_bin3'] = pd.cut(x = df['horsepower'],
bins = 3,
labels=False
)
df['hp_bin4'] = pd.cut(x = df['horsepower'],
bins = 3,
labels = ['저출력','보통출력','고출력'],
ordered=False
)
df['hp_bin5'] = pd.cut(x = df['horsepower'],
bins = [80,100,200,300],
labels = ['저출력','보통출력','고출력'],
)
df['hp_bin6'] = pd.cut(x = df['horsepower'],
bins = [80,100,200,300],
labels = ['저출력','보통출력','고출력'],
include_lowest=True
)
df['hp_bin7'], bins = pd.cut(x = df['horsepower'], # 데이터 배열
bins = [80,100,200,300], # 경계값 리스트
labels = ['저출력','보통출력','고출력'], # 구간 이름
right=False,
retbins = True
)
display(df)
print(bins); print()
print(df['hp_bin4']); print()
print(df['hp_bin5'])실행결과
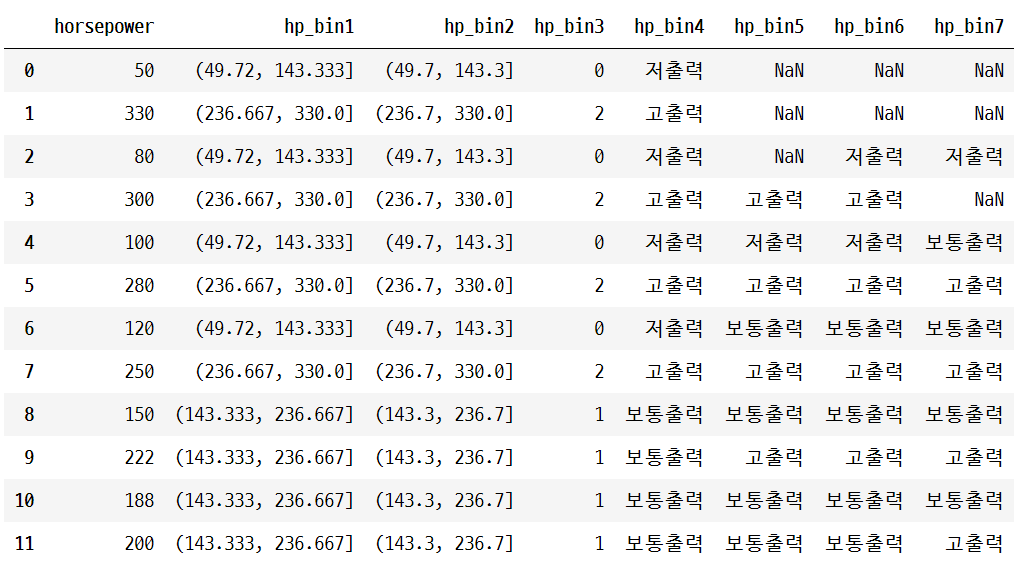
[ 80 100 200 300]
0 저출력
1 고출력
2 저출력
3 고출력
4 저출력
5 고출력
6 저출력
7 고출력
8 보통출력
9 보통출력
10 보통출력
11 보통출력
Name: hp_bin4, dtype: category
Categories (3, object): ['저출력', '보통출력', '고출력']
0 NaN
1 NaN
2 NaN
3 고출력
4 저출력
5 고출력
6 보통출력
7 고출력
8 보통출력
9 고출력
10 보통출력
11 보통출력
Name: hp_bin5, dtype: category
Categories (3, object): ['저출력' < '보통출력' < '고출력']더 많은 예제를 보려면 Example & the user guide를 참고하세요.
주의사항
모든 NA 값은 결과적으로 NA가 된다. 범위를 벗어난 값은 반환되는 Series 또는 Categorical 개체에서 NA가 됩니다.
참고 사항
qcut순위 또는 샘플 분위수를 기반으로 변수를 동일한 크기의 버킷으로 이산화합니다.
Categorical고정된 값 집합에서 가져온 데이터를 저장하기 위한 배열 유형입니다.
Series시리즈축 레이블이 있는 1차원 배열(시계열 포함).
IntervalIndex구간인덱스정렬되고 슬라이스 가능한 집합을 구현하는 불변 인덱스입니다.
'Python 파이썬 > pandas' 카테고리의 다른 글
| pandas ) 자료형 변환 함수 astype() (0) | 2022.04.18 |
|---|---|
| pandas ) 특정 요소 변경 replace() 함수 (0) | 2022.04.12 |
| pandas ) 중복 데이터 처리 duplicated(), drop_duplicates() (0) | 2022.04.04 |
| pandas ) 누락 데이터 처리 isnull(), dropna(), fillna(), replace() (0) | 2022.04.04 |
| pandas ) 판다스 내장 그래프 도구 (0) | 2022.03.22 |
댓글